
In this post I'd like to present a slightly different take on AI and expose one dimension of Intelligence which we hardly explore with mainstream efforts. In order to do that, I'll use a metaphor, which should hopefully make things clear. As with every analogy, this one is also bound to be imperfect, but should be sufficient to get certain idea across.
The metaphor
The way I see progress in artificial intelligence (AI) could be summarized with the following (visual) metaphor:
Imagine that elevation symbolizes ability to accomplish certain level of performance in a given task, and each horizontal position (latitude/longitude) represents a task. Human intelligence is like a mountain, tall and rather flat, just like one of those buttes in Monument Valley. Let's call this mountain "Mt. Intelligence". A lot of horizontal space is covered by the hill (representing the vast amount of tasks that can be accomplished), less intelligent animals can be represented by lower hills covering different areas of task space.
In this setting our efforts in AI resemble building towers. They are very narrow and shaky, but by strapping together a bunch of cables and duct tape we can often reach elevation higher than the "human level". At that point everybody euphorically shouts about "super-human AI" and threatens people with Skynet.
But as soon as somebody wants to apply those "towers" to tasks slightly beyond what they were designed for, they find themselves falling down. Even to accomplish a relatively similar (nearby) task, one has to build another tower, often from grounds up.
The problem is that, although we can sometimes reach or even exceed "human level" (as we did with Chess or Go and numerous other narrow tasks), the solutions we build are extremely brittle. And frankly, this entire horizontal dimension of "intelligence" remains fairly undefined and unexplored land.

{kind=link}
The land
Following the metaphor, the horizontal spread of Mt. Intelligence symbolizes vast amount of qualities intelligence has, many of which have not been very well quantified or even verbalized at all. To give a concrete example let us focus on visual perception, notably an important aspect of general cognition. What is vision? Generally speaking it is ability to convert visual input into a useful/successful behavior. Although this may capture the broad spirit of vision, it is not easy to quantify (what is successful behavior anyway?), consequently a more specific benchmark task can be devised. Particularly in machine learning, vision tends to be stripped out of the behavior part entirely and treated as classification/localization problem (one could argue that the label readout is a highly impoverished version of behavior). E.g. the ImageNet dataset widely used as a benchmark for "visual cognition" focuses on object classification and localization. Does human vision perform object classification and localization? Certainly so, since that dataset was labeled by humans to begin with. But aside from that, human vision does a myriad of other things, e.g:
- localize and classify the source of illumination in the scene
- localize shadows, assign shadows to individual sources of illumination, assign shadows to object casting them
- identify reflective surfaces such as mirrors
- identify semi-transparent surfaces, refractions
- identify flat surfaces and defects in those surfaces
- fuse two 2d images into a very usable (though arguably rough) depth map
- determine consistency of shadows, spot outliers
- ...
and potentially much more. All of these tasks can actually be accomplished by humans looking at static pictures, similarly to object classification as done in ImageNet, so these things don't even require access to temporal dynamics of the scene (at least at the inference stage). The point is, there are various tasks being solved simultaneously and likely each of these tasks can vastly improve performance of all the others. This shows the extent of Mt. Intelligence in visual context, while ImageNet classification task symbolizes a single, narrow spike we planted a "super human AI" flag on. We can solve object classification OK, but much of listed above remains elusive (partially because there are no big labeled datasets for those tasks).
But the list above does not even begin to scratch the surface of what visual cognition accomplishes. When extended into temporal dimension, human vision also:
- identifies and localizes looming objects
- identifies and localizes objects moving with respect to observer and the rest of the scene
- maintains identity of tracked object
- identifies depth based on differential motion and axis shift
- identifies reflections and flares based on their motion
- identifies rigid bodies based on the coherence of motion
- identifies hollow or lightweight objects based on their motion
- identifies fluid/smoke based on fluid like motion
- ...
Again the list could continue further, with large number of these tasks not even easy to verbalize. Similar argument is true for other modalities and pretty much every aspect of cognition. In various well defined spots we can reach human level, but apparently we cannot cover any significant area of tasks at once.
The elusive inequality
What further distorts our perception of contemporary capabilities of AI is the uneven distribution of difficulty of problems. To give a concrete example again: for much of the time humans don't need their brain at all. Any time you feel comfortable, you are not endangered in any way, you are not generating any behavior, from external point of view a dummy would do just as well. And then obviously comes the time when you need to generate behavior at which point you need your cognitive capabilities. Imagine driving on a straight desert freeway: you may adjust the steering wheel every few seconds just to remain in the lane, but really you don't need a fraction of the full human cognitive capacity to do that (hence people daydream while driving). Then after a few hours you enter a busy town, where some unusual thing is happening and suddenly you need a much better understanding of what is going on in order to remain safe. If you were to plot the cognitive difficulty over time, likely the plot would be very unbalanced: very low for very long stretches of time and then with occasional spikes into the stratosphere. You really need intelligence only when the situation demands it. But when that happens, you better have it, otherwise you may very quickly find yourself in serious trouble.
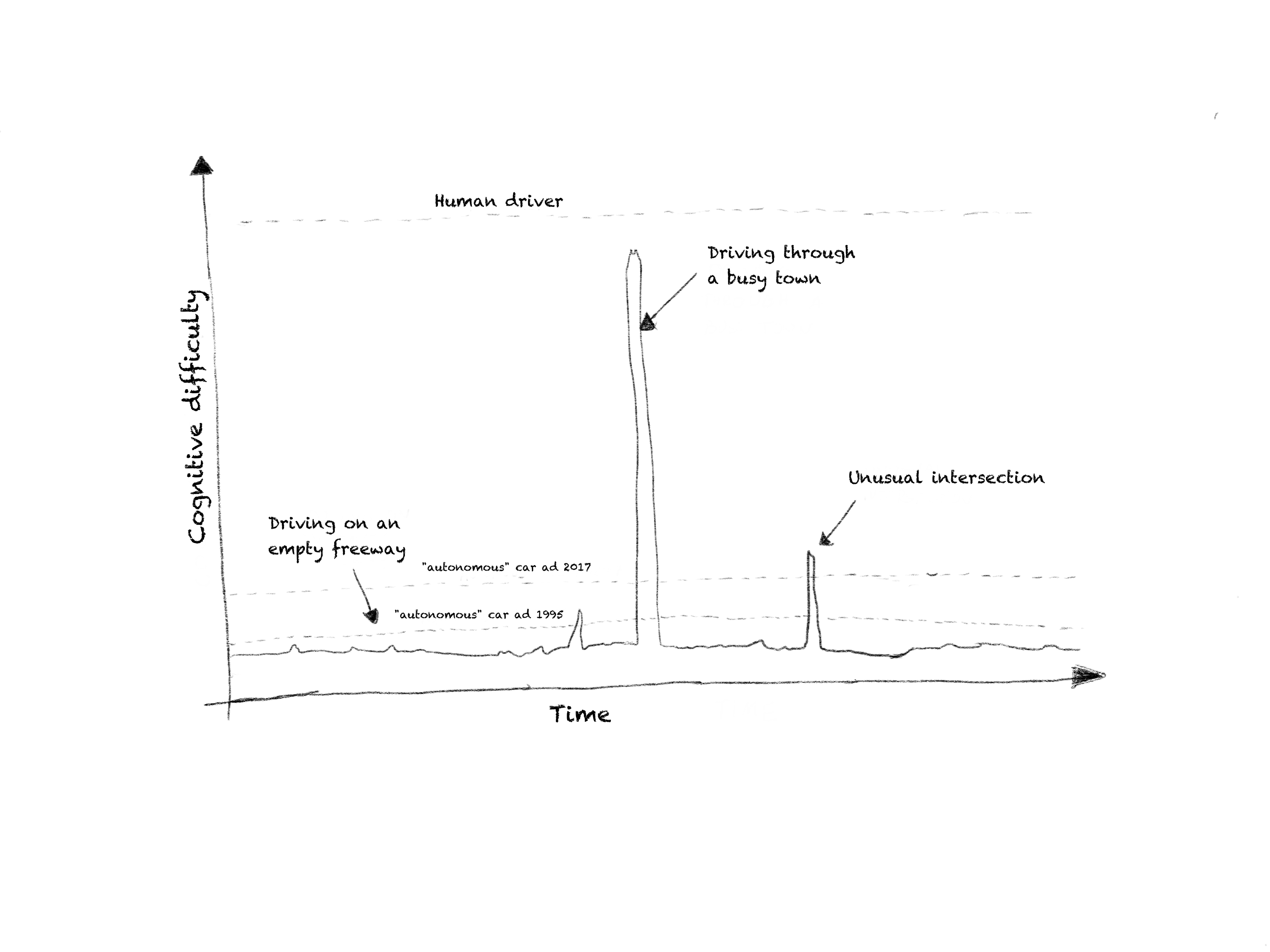
The reason why this is confusing, is visible quite clearly with self driving cars. Since most driving reality is simple (freeway), relatively unsophisticated systems can handle huge percentage of driving, say 90%-99%. Even back in the 90's first semi-autonomous cars had driven through the US, being auto-steered 98% of the time (No hands across america -yes you read this right, that was in 1995!!!). And then comes the remaining 1-2% of increasingly difficult situations (often called corner cases), where progressively more and more of cognition is necessary. With the current approach, these corner cases are being slowly worked around by either using better sensors or various pre programmed heuristics or hacks. The entire bet on self driving car is that eventually we will strap together enough of these contraptions, that it will be "good enough". But "good enough" is a very high bar in this case - humans are actually very good, particularly in dealing with and anticipating other human actions, while the potential consequences and liabilities could be devastating! The height of that bar may also depend severely on the type of environment where such autonomous vehicle would move around and the general anticipated conditions. There is a small probability that this approach would work, and eventually such autonomous vehicles could become practical, but more likely they will remain very limited, expensive and hence not particularly attractive (beyond niche applications).
Piling up rocks
Could there be a different approach to addressing AI, other than building these tall, fragile and extremely narrow towers, strapping them together with a bunch of tape in hope of covering enough area? I believe so, and I think ultimately such approach will prove much more productive. But there is a difficulty: if we go back to the original metaphor, the alternative solution is to start piling up tons of rock and sand in order to eventually build a solid mountain as tall Mt. Intelligence. This way, ultimately there will be no holes and wide area will get covered. But in order to do that, we have to go back and ask ourselves: what is the task solved by cognition/intelligence, in other words how to cover a meaningful area without verbalizing each task (e.g. via creating a huge labeled dataset)?
To be concrete, let us go back to visual perception and the list of tasks above. Is there any "golden task" that, when solved, would have also solved all of the tasks listed and more? Can we formulate something as general as that? I would argue that yes, and it actually is right in front of us (hence perhaps so difficult to see). The common theme between all the aspects of visual cognition I listed is that all those task are simple if we had a model representing the visual scene in question (that is representing the physical causes/actors that lead to that particular scene). If for every picture we had something like a CAD model of the reality that rendered that particular stimuli: with all the surfaces and lights somehow represented, all of these tasks are becoming almost trivial. Such model could be built explicitly, and this is often done in robotics (including autonomous vehicles), but It could also get imprinted in a machine learning structure (say a giant neural network), with appropriate optimization criteria (loss function). And that loss function is not very complex either - the one I propose is "temporal prediction error".
Similarly to scientific theories (which are, by the way, formal models of reality), a good model can make predictions that turn out to be correct. If a theory makes wrong predictions, it needs adjustments. Similarly a neural network with sufficient expressive power (recurrent structure allowing it to make connections between various aspects of observed reality) could build an internal model of observed signals. This is not a very radical idea! In fact such models of reality are known in robotics for decades under the moniker "forward model". Additionally there is a ton of evidence from neuroscience and behavioral psychology that this is indeed what is very likely going on in our brains (neocortex in particular).
Moreover, our initial studies show what one could successfully train a large recurrent neural network with such predictive paradigm, and get many layers of stable and informative representations that could be read out for various tasks.
But there is a problem: while piling rocks, it is hard to make a very lean, tall tower (and tall tower are the only thing that sells). With this approach there will not be many flashy headlines of the sorts of "human level capability in [put your extremely narrow task of choice here]". It will potentially take many years, maybe even decades before we can reach "general human level performance" with this approach. Yet in the end I think this approach will outperform our current AI hacks much like deep learning outperformed feature engineering and formal methods. For the time being a hybrid approach in which "the pile of sand served as a base for another shaky tower" could also work, to deliver incremental improvements on our existing technology.
Nouvelle AI 2.0
As with everything in the world, there has been prior art - namely the Nouvelle AI movement proposed in the 80's at MIT. The spirit of that movement was to build basic perceptual and behavioral capabilities in robots such that they could accomplish behaviors similar to insects. The behaviors would not necessarily be very sophisticated, but the idea was to make them very robust - in essence piling up "insect height" pile to follow our analogy. This approach was lead by Rodney Brooks who later started iRobot and created roomba vacuum cleaner, which arguably does behave like a fairly primitive insect and is certainly pretty robust in what it is doing. There are however subtle differences between Nouvelle AI and what I'm proposing here, so I'll call this approach Nouvelle AI 2.0. In the 80's the discussion was primarily between symbolic AI which stated that intelligence is a quality arising from abstract symbols and situated activity (grounding hypothesis) which postulated that these symbols need to be grounded in physical reality and in fact it is best if there is no symbols at all, rather a constant interaction with physical reality (refer to classic paper by Rodney Brooks "Elephants don't play chess" for details). Although the details have changed and we shifted from pure logic to connectionist models (such as neural networks), remnants of the original discussion still ring quite loud. To put it most simply - we no longer insert symbols and their semantics into giant databases to have the machine reason on them, but we impose those symbols as an output of training of a neural network. Bottom line, we still impose what we think the system should learn/represent, rather than let the system figure on its own what it should learn, partially because we don't have a valid optimization criteria for what the system "should learn".
So given the things that have changed, here are a few postulates I'd like to include in this proposed Nouvelle AI 2.0:
- The system should learn in a constant closed loop with the environment
- The system should be allowed to act and explore the consequences of it's actions
- The primary objective of learning is building a "forward model" of reality surrounding the agent (and the agent itself). The design of the learning substrate should be such to facilitate creation of best such model possible. A better model should allow for readout of multiple tasks at once.
- The primary readout from the system should be behavior, though other readouts could be possible, to understand what the system is able to represent (and improve on the model).
- The design of the machine learning substrate has to be very scalable, should not be constrained by things such as vanishing gradient
- If we have to impose symbols we should do that at a high level of abstraction, which is where human level symbols belong. The system should be able to connect these symbols with the representations generated by its forward model, otherwise these symbols will remain abstract and therefore not robust.
- It is important to build a system that can solve simpler problems more robustly before we proceed to system able to solve more complex problems - an autonomous robot which can play chess is useless if it cannot sit by the table or open door knob - as is the case with contemporary robots which renders them highly unusable.
- There is no single silver bullet (such as say reinforcement learning). Reinforcement learning will certainly be a part of that puzzle, but likely at a higher level when planning is involved, not in basic perception/action.
- We may need to preprogram certain basic instincts, such that the agents don't do foolish things. The same happened over billions of years with animals via natural selection.
Conclusion
The approach I'm proposing is not excluding any particular method to accomplish these objectives. I'm not against deep learning, it is extremely useful and could be used here as well. To go back to our analogy, I'm not against using any particular material for our pile, but rather for building a broad and solid thing instead of shaky tall towers, even at the cost of not reaching the heights for a while. This approach requires abandoning the arrogance many AI researchers demonstrate while promoting their contraptions as "human level AI", hence will be criticized by those with vested interest in pumping up AI bubbles. But bubbles eventually burst, winters come and problems remain. We need to move on.
If you found an error, highlight it and press Shift + Enter or click here to inform us.